


HasData
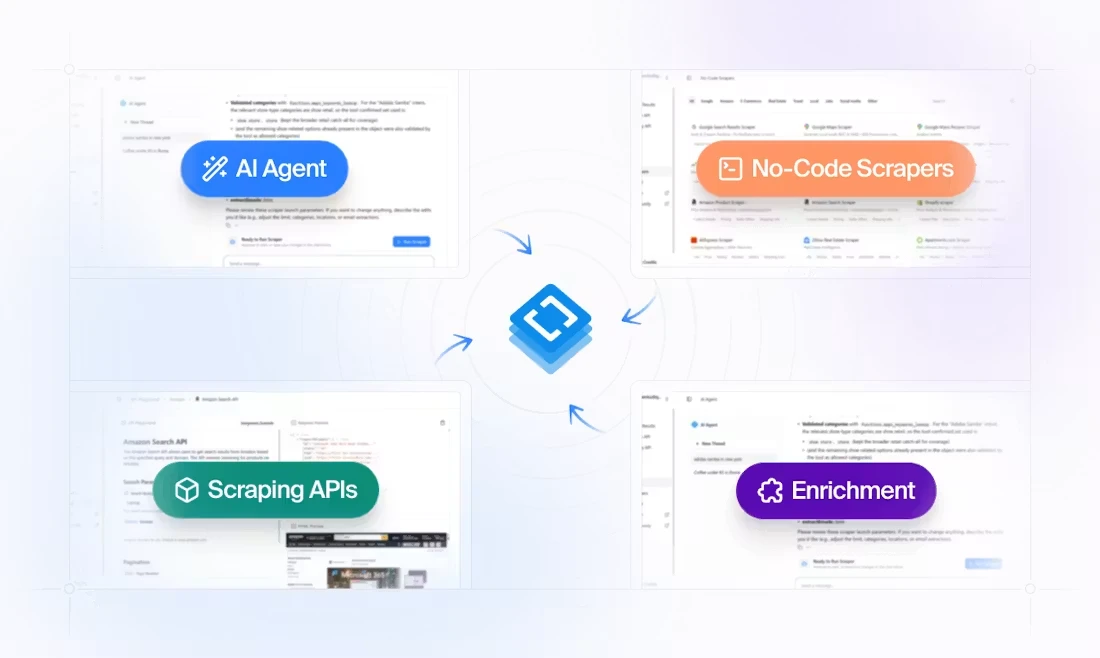
HasData is a managed web scraping infrastructure designed for developers, AI agents, and data pipelines that need reliable access to structured web data without building and maintaining scraping systems from scratch.
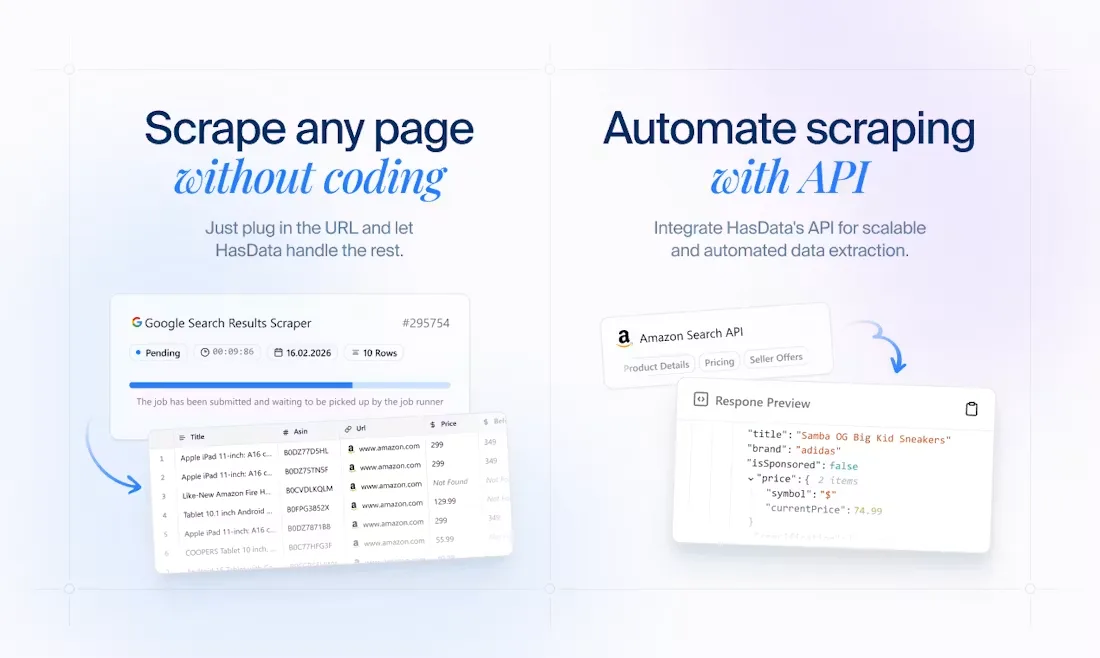
Instead of dealing with proxies, browser automation, retries, or anti-bot systems, users can simply send a URL and receive clean, structured output in JSON or Markdown through a single API call. This makes it significantly easier to turn unstructured web pages into usable data for applications, analytics, or AI workflows.
The platform also provides a library of prebuilt scrapers for common sources such as Google Search, Google Maps, News, Zillow, Indeed, and major e-commerce platforms. For more complex or custom websites, HasData includes AI-powered extraction that can interpret plain-text instructions and return structured results without needing manual selector configuration.
A key part of HasData’s positioning is its compatibility with AI systems. It can be used directly from tools like Claude, ChatGPT, or custom AI agents through MCP or API integrations. This makes it particularly useful for agent-based workflows where real-time web data is required as part of decision-making or content generation.
For developers who prefer command-line workflows, HasData also provides a CLI interface, making it flexible enough to fit into both traditional backend systems and modern AI-driven architectures.
Overall, HasData abstracts away the complexity of web scraping and turns it into a simple, query-based data service, enabling faster development of data-heavy applications and AI agents that rely on live web information.